1. 概要
コインチェック株式会社(以下コインチェック)インターンの中許と申します。今回は、BigQueryの利便性を向上させるため、Gemini API (以下Gemini)を用いてテーブルデータの説明文を生成・付与した取り組みについてご紹介します。(状態・ステータスの単語を一致させる)
2. 取り組んだ課題
コインチェックのデータ基盤には、Google Cloud の BigQuery を利用しています。社内でのAI・MLの活用を見据えて、AI・MLファーストなデータ基盤にしていくために、BigQueryテーブルのメタデータを充実させる対応を行いました。データ基盤にある大量のテーブルとカラムに十分な量の情報を付加することにより、AIによるテーブルデータの解釈精度を高めることができます。
ビジネスメタデータを充実させることによる効果について、詳しくは吉田さんの記事をご覧ください。

弊社では、生成AIを活用して自然文からSQLクエリを作成できるようにしています。これにより、SQLに慣れていない方であっても、SQLを作成して容易にデータ分析を行うことができます。
テーブルデータの説明を充実させることは、この自然文によるSQLクエリの作成精度を向上させ、現場の様々なスタッフによるデータ分析のセルフサービス化を促進することに寄与します。

3. ゴール設定
3.1 データの種類
テーブルデータには異なる性質のデータが存在しますが、今回はデータを”カテゴリカル変数”と”非カテゴリカル変数”に分け、カテゴリカル変数のカラムにフォーカスし、説明文を生成しました。
カテゴリカル変数とは、男女のような区分を1、2などの名義尺度で表したものです。弊社には多くのカテゴリカルなデータがあり、ユーザの性別や職業、職種などのデモグラ情報、取引した暗号通貨や取引種別、取引の内容などについて、1、2などの数値で情報を記録しています。

3.2 2段階の目標
“BigQueryのカラムに説明文を追加し、カラム情報をリッチにする”ために、次の2段階の目標を設定しました。AI・MLファーストなテーブルデータを構築する過程で、ヒトにとってもフレンドリーなデータ基盤になることを目指しました。
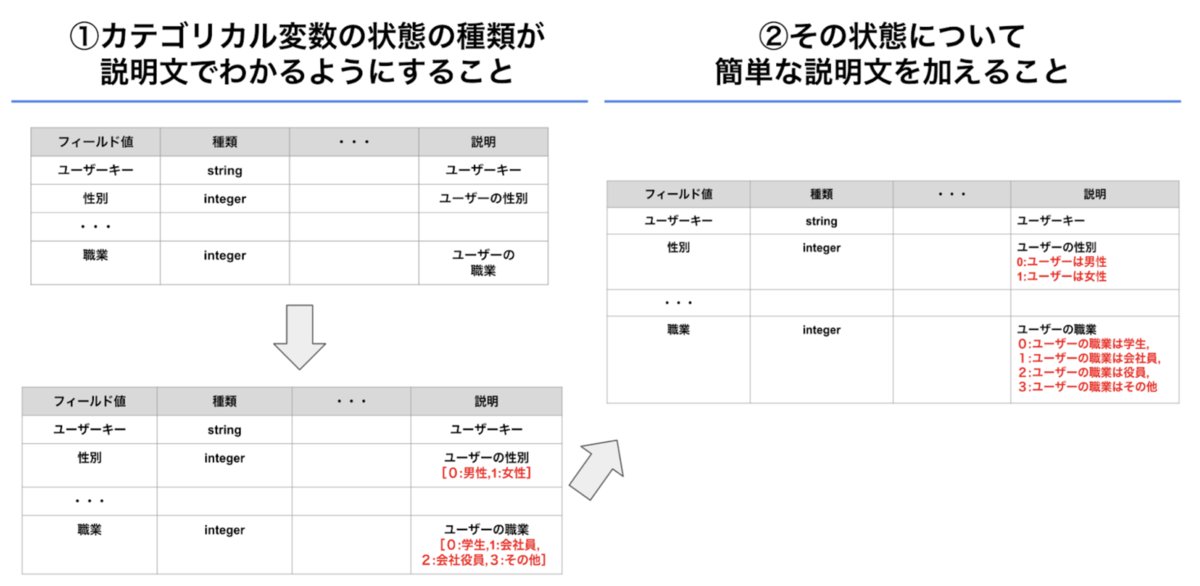
- カテゴリカル変数の状態の種類が説明文でわかるようにすること
- その状態について簡単な説明文を加えること
4. 実装内容
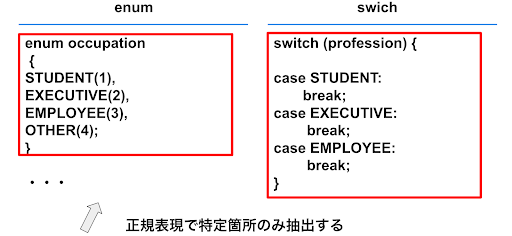
4.1 パターンマッチングによる特定箇所の抽出
テーブルデータのカラム生成元であるソースコードから、カテゴリカル変数の定義箇所をパターンマッチングにより抽出しました。パターンマッチングとは、対象となる文字列から特定のパターンを検出する方法です。各カラムに数値を格納するコードではカテゴリカル変数をenumやswich文で定義していました。したがって、正規表現では複数パターンのenumやswich文を記述することで、コードからカテゴリカル変数の定義箇所をパターンマッチングにより抽出することができます。
余談ですが、コードから特定箇所を抽出するプロセスでは、Geminiを利用する方法も試みました。パターンマッチングは指定した正規表現の記述には確実にマッチできる一方で、少しでも形の異なる記述の抽出には対応できず、抽出漏れが発生します。このことから、Geminiを利用し、複雑な記述にも対応して抽出しようとしました。
しかしながら、Geminiを利用した結果、カテゴリカル変数の抽出にはハルシネーション(=それっぽい嘘)が含まれていました。具体的には、存在しないカテゴリカル変数の状態が作成されていました。ハルシネーションは実行するプロンプトを改善することで抑制できる可能性があります。一方で、たとえハルシネーションの発生確率が低くても、数百個数あるカテゴリカル変数ではハルシネーションが起こらないといえません。そのため、今回は正規表現を増やしてあらゆるパターンの記述に対応できるようにして、抽出漏れを対策しました。
4.2 Geminiによる説明文の生成
パターンマッチングによって抽出したカテゴリカル変数を元に、Geminiで説明文を生成しました。プロンプトは次のようにしています。具体的にプロンプトでは、パターンマッチングによって抽出した箇所である”ステータス”や”状態”に加え、そのソースコードの名称を与えました。さらに、Few Shotで複数の入力例と出力例を与えました。
ソースコードの名称(下記プロンプトではtableカラム)を加えることで、カテゴリカル変数の説明文生成にメタ情報を加えることができます。以上のようにして、抽出したカテゴリカル変数の説明文を生成しました。

5. 苦労した点&工夫した点
5.1 生成AIによる表記ゆれ
「4.2 Geminiによる説明文の生成」に記載したプロンプトでは「日本語で」という言葉を入れています。これはGeminiによる生成文の出力が、ごく稀に韓国語や中国語で表示される事象を回避するためです。しかしながら、プロンプトも虚しく日本語以外の言語で出力されることがあります。
このような事例に対応するために、生成された文章に特定の文字コード以外の文字(=韓国語、中国語等)が含まれていれば、再試行する仕組みにしました。
5.2 テーブルデータとソースコードの紐付け
BigQueryのテーブルとアプリケーションコードでのテーブル定義の名称が完全には一致できておらず、テーブルと該当のソースコードを紐づけることに苦労しました。ソースコードからステータスや状態をせっかく抽出できても、その定義がどのテーブルのものか機械的に判断できず、BigQueryのテーブルに反映することができませんでした。
結果的に、ソースコードのディレクトリ名を活用することで、BigQueryのテーブルに一意に紐づけることができました。プロダクトによってアプリケーションのソースファイルやテーブルの命名規則は異なると思いますが、こうした機械的な処理を行うことも考慮し、決められた規則に則った構造をさせておくことが重要だと思います。
5.3 手動。ダメ。ゼッタイ。
本実装は最終的にAirflowのDAGに組み込み、テーブルデータの説明文を定期的に自動更新するようにしました。これは、新たなアプリケーションコードの追加や変更に対応するためです。
手動による更新では運用コストが大きいため、先述したようなGeminiで意図しないレスポンスがあった場合などにも、全てのフローで手動修正を必要とせず、自動でリカバリできるように工夫しました。
データ分析者の生産性をあげるために、データ基盤グループが都度手動修正をすれば、データ基盤グループの運用負荷が高くなってしまい、組織全体の生産性をあげたことにならないので、運用負荷をあげることなく、分析者にも恩恵のある実装をすることが大切だと思います。
6. 今後の展望
今後、本取り組みでは対象外とした非カテゴリカル変数のカラムについても、ひきつづきリッチ化に取り組んでゆきます。
弊社のデータ基盤の全体像については、岩瀬さんの記事でご紹介させて頂いておりますので、ご興味ありましたら、そちらもあわせてご覧ください。
本記事をお読みいただき、誠にありがとうございました。