コインチェック株式会社(以下、コインチェック) データ基盤グループの岩瀬です。今回は、暗号資産交換業者であるコインチェックで実施したデータ基盤のリプレイス事例と、そこから連続するデータ基盤拡充の取り組み、データドリブンな組織への貢献についてご紹介します。
TL; DR
- 暗号資産取引所を運営するコインチェックでは、運用されていたデータ基盤を、限られた技術リソースと短期限でモダンにリプレイスし、結果 インフラコスト90%削減 を実現しました。
- Treasure Data で構築されていたデータ基盤の移行先として Google Cloud を選定し、3ヶ月で既存と同等のシステムを構築 して並列運用を実現し、システムのリプレイスが可能であることを示しました。
- 以後データ基盤の拡充を進め、社内で生成される各種データのデータレイクへの集約、それらを活用したダッシュボードの構築、データ分析環境の整備、データガバナンスの強化などを通じて、データドリブンな組織の実現と、その先の成長を支えるための活動を続けています。
コインチェックとは

新しい価値交換を、もっと身近に
コインチェックは、2014年8月に暗号資産取引サービス「Coincheck」を開始して以来、金融リテラシーにかかわらず、誰でも使いやすいサービスを提供することにより、「新しい価値交換」を身近に感じられる機会をお客さまに届けてきました。コインチェックは、暗号資産やブロックチェーンにより生まれる「新しい価値交換」、またその次に現れる新しいテクノロジーにより実現される変革を誰もが身近に感じられるように、より良いサービスを創出し続けます。
1. データ基盤リプレイスの背景と目的
暗号資産取引サービスは、業界全体が急速に成長している中で、競合他社との激しい競争にさらされています。新通貨の上場や新サービスの展開に加え、監督省庁からの規制要件への対応が常に求められ、金融機関らしく、品質に対する要求も非常にシビアです。
そうした各所の要求に応えることが優先されるため、エンジニアリソースは常に逼迫しており、業務改善プロセスや、システム構成の見直し、今回お話しする社内のデータ利活用やコスト最適化の対応は後手に回りがちです。
一年前の2023年秋には暗号資産市況は冬の時代にあり、上記のような状況下で、厳しい収益状況に耐えうる体質を目指す中でデータ基盤にも見直しの機運が高まり、費用削減を主な目的としてデータ基盤リプレイスのプロジェクトが立ち上がりました。
コスト構造
2023年当時データ基盤は Treasure Data を利用していました。
Treasure Data は企業向けのデータ基盤を提供しています。非エンジニアが多様なデータソースを連携してデータ基盤を構築できる点に強みがあり、コインチェックでも、エンジニア負荷を少なく抑えられる点や、データ基盤が急ぎ必要とされた状況で採用されました。
データ取り込みやマシンリソースに対する課金が中心で、利用者数や使用頻度に関わらず一定の費用がかかる課金体系になっており、十分なデータ利活用が進まなければ費用対効果が得られない構造でした。
2023年当時のコインチェックでも、少ない利用者数でデータ基盤が十分活用できていない状態ながら、安くない固定料金が発生していたため、このコスト構造は見直しが必要とされました。
専任者と経験者の不在
過去に基盤導入した担当者はすでに退職しており、運用する専任エンジニアもいない状況でした。
他業務を主務とするエンジニアが兼務して運用を行っており、リクエストベースでの対応が中心で、データ基盤のリファクタリングやモダン化に踏み込むにはリソースが足りませんでした。
性能の課題
システムのパフォーマンスにも課題がありました。
Treasure Data は Hadoop などのクラスタ上に構築された基盤でクエリを実行しますが、当社での利用方法においてはGoogle BigQuery などのレスポンスと比べると低速なパターンが多く、大量のクエリを同時に処理する際には待ち時間も発生していました。
当社は日次処理を日中決まった時間に集中して行っていたのですが、この集計の動いている時間帯はカジュアルな分析クエリを待たせることになるため、分析者にはストレスがかかる状況でした。
今後データ利用者と利用機会を増やしていくにあたっては、困難があることが予想されました。
外部サービス連携やシステムの拡張性
Treasure Data を基盤とした上で、例えば機械学習モデルを生成したり多様なデータを柔軟にカスタマイズして取り込んだりしようとした場合、追加費用が必要になったり、仕様にあわせた調整が必要になったりなど、拡張が容易でない状況がありました。
社内で活用されている Google Analytics との連携や Google Spreadsheet へのデータ出力などでも、認証に煩わしさがあり、UI/UXの観点で、分析者が手軽にデータ利用できる状況は実現できていませんでした。
根本解決
運用面でもコスト面でも課題がありながら、リソースの問題で長年解消できない状況が続いていたため、今プロジェクトでは、リソースを確保して根本解決することが求められました。
大幅にコスト削減することに加えて、社内のデータ利用者のストレスを軽減し、運用負荷を軽減すること、これらを包括的に解決し、その後の積極的なデータ利活用に資する体制を構築するうえで、データ基盤のリプレイスは不可欠と考えました。
2. アーキテクチャと技術選定プロセス
アーキテクチャの要件
タイムラインについては次章でも触れますが、このプロジェクトの開始時点で重要なマイルストーンがひとつ決まっていました。Treasure Data 社との契約更新は2024年2月にあり、解約の場合は2023年12月末までの通知が必要でした。
検討を始めた段階ですでに9月であり、新アーキテクチャへリプレイス可能かどうか、開始から3ヶ月で見極めなければならないスケジュールでした。
データ基盤の周辺部分も含めて綺麗に直すか、使える部分はできるだけ残して必須となる部分だけリプレイスするかは要件次第ですが、時間も限られるため、自身のこれまでの経験もふまえて、既存システムのアーキテクチャを見て、効果の大きい箇所はリプレイスしつつ、既存のものでそのまま使えるものは残す(別の機会に棚上げする)ことにしました。
コスト見積もり
既存システムのクエリ実行数、対象となるデータサイズなどから、移行後のデータ参照量を見積もりました。
扱ったことのある実績から AWS Redshift と Google BigQuery が選択肢として残っており、どちらも費用を見積もりましたが、どちらであっても単純に移行するだけで大幅なコスト削減になる見込みが立ちました。
作業見積もり
リプレイス可能かどうかは、既存で動いているシステムの入力と出力が同じになることを示せば良いと考えました。このことから、既存システムと新システムを並列に立ち上げ、これらの出力結果に差分のないことを検証する方法を取ることとしました。
3ヶ月(で検証を終えるので構築には2ヶ月程度)で既存システムと同等のシステムを構築して結果を出さなければいけないのですが、クリティカルなワークフローとコンポーネントに絞って検証する計画を立て、作業見積もりをし、チャレンジングではあるものの実現は可能と判断しました。
(AWS Redshift、Google BigQuery どちらの構成でも作業コストはあまり変わらない見積もりでした)
アーキテクチャの決定
社内にはアナリストのグループがあり、データ利用する際の操作性や通常業務で利用しているGoogle Spreadsheet や Looker Studio などとの連携が円滑であることを理由に、Google BigQuery の採用を希望されていました。
外部連携のしやすさ、パフォーマンスの期待、アナリストが多くの時間を費やす分析業務の効率向上に寄与すると考え、総合的に、Google BigQuery を採用することに決まりました。
リプレイスが実現できればどんな方法であれコスト削減が実現できる見込みであったため、リプレイスの実現可能性のみが懸念でしたが、この検証は3ヶ月あれば十分可能と判断し、プロジェクトを開始しました。
構成
システム構成図:旧システム

上図の中央、紫部分に Treasure Data のデータ基盤があり、主にアプリケーションが運用されている AWS からデータが収集され、分析できる環境を提供しています。
サービスに関わる数値のダッシュボードが Looker Studio で作られ、Amazon ECS 上で起動している Airflow により日次のデータ更新が行われていました。
ログデータなど基盤に取り込まれていないデータも存在し、社内で権限をもつユーザがストレージからデータ取得してローカルで分析するなどのフローもありました。
システム構成図:新システム
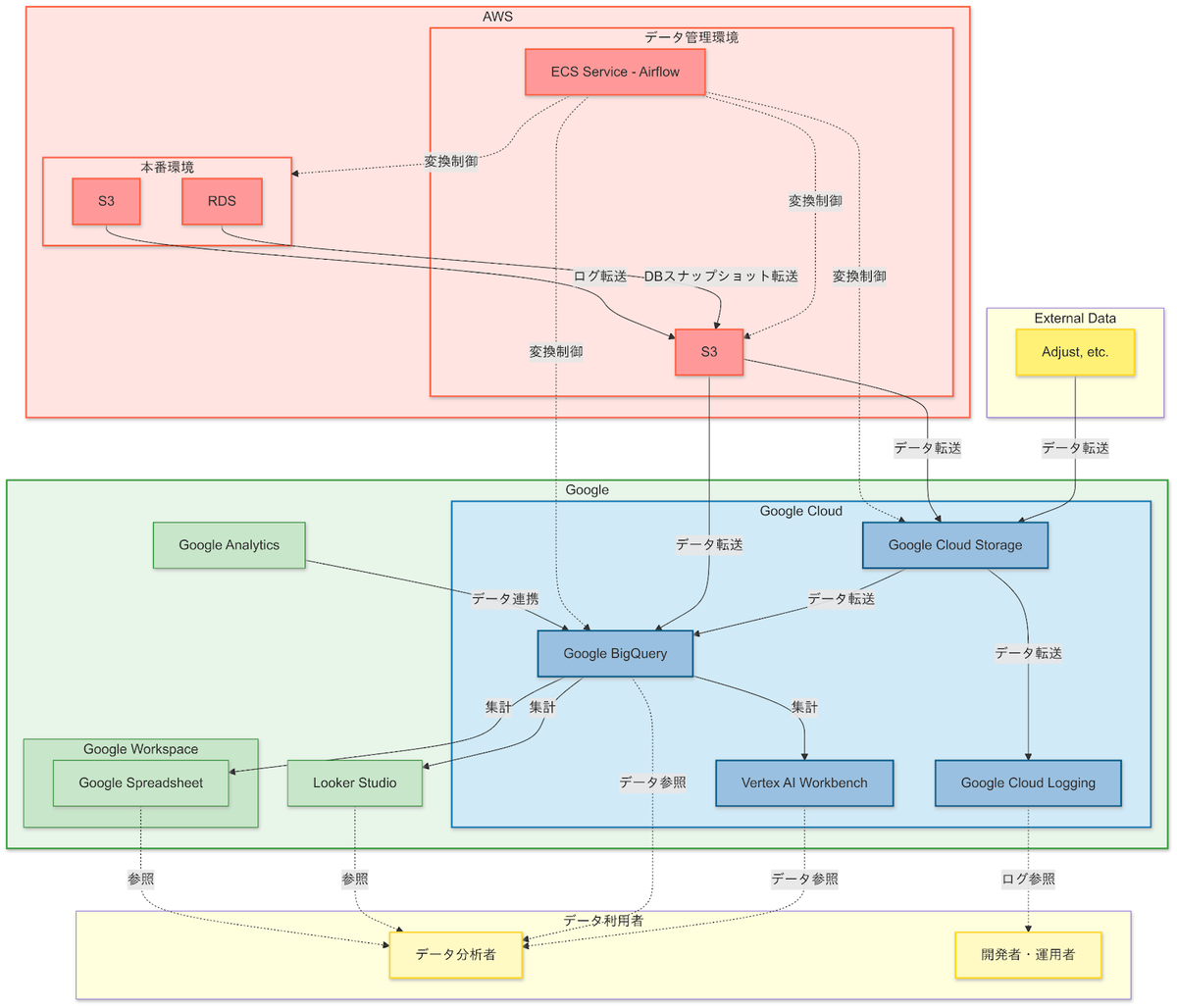
構成図の Treasure Data の部分が Google Cloud に置き換わっています。
元々 Looker Studio や Google Spreadsheet は社内で利用されていたものの、連携が複雑で煩わしかった部分が整理され、社内の一般ユーザにも利用しやすいものになりました。
またユーザの認証システムが統一されていなかった部分も、Google Workspace によるID統合で、一元的に管理できるようになりました。
要素の概要
主要な構成要素について解説します。
ワークフロー管理
Apache Airflow
データパイプラインやワークフローをスケジュール、監視、および管理するためのオープンソースのプラットフォームです。複雑なデータ処理のワークフローを簡潔に記述し自動化するために広く使われており、スケジュールされたタスクをプログラム的に定義して実行できます。
既存のシステムに組み込まれており、AWS 上でデータの加工を行うなどの要件上も都合がよかったため、そのまま存続させることとしました。
リプレイスにあたっては、Google Cloud Storage や Google BigQuery へ入出力するDAG プログラムを書き、Treasure Data 向けの更新処理と同じ挙動になるように実装しました。
DWH
Google BigQuery
Google Cloud上で提供されるフルマネージドなデータウェアハウスで、大規模なデータの高速クエリ処理ができます。SQLベースのクエリを使用してペタバイト規模のデータに対してリアルタイム分析を行い、スケーラビリティやパフォーマンスに優れています。データ参照量に応じた従量課金の課金体系です。
インフラ
Terraform
インフラは構築時から Terrafiorm でコード管理を行い、変更履歴は git から参照できるようにしました。
BigQuery のスキーマに関しては構築完了まで流動的になることが予想されたためTerraform 管理の外におき、クエリ等と同様のリポジトリに管理することとしました。
AWS
コインチェックサービスのインフラは基本的にAWSで構築されており、ソースとなるデータ群もAWSのインフラ上に存在します。
production 環境からデータを抽出することには厳しい制約があり、踏み台となるデータ管理環境を経由して、データを加工した上でのみAWS外へ持ち出すことが許可されます。既存のこの統制は踏襲したうえで、Google Cloud へデータを抽出する構成にしています。
Amazon ECS
Apache Airflow のサービスを起動してワークフロー管理を行なっており、個別のタスクはECS Task を起動することで実行します。
上記統制に従ってデータ加工する仕組みはAWS内に閉じておく必要があり、既存のプロセスを踏襲してECS上のプロセスでデータ抽出・変換の処理を実行させ、Google Cloud への出力も管理しています。
Amazon S3
production のS3 バケットにはアプリケーションで発生する多数のログやファイル、インフラのレポートなどが存在し、それぞれ production から抽出したデータを踏み台に加工した状態で一時保存し、Google Cloud へ転送します。
Google Cloud
Google BigQuery
サービスで利用されるほぼすべてのデータベースのデータと、多くのログを集約したデータウェアハウスです。SQLによって分析クエリを投げることができ、結果をSpreadsheet に出力したり Looker Studio へ送って可視化するなどの連携が容易にできます。またGoogle Analytics をはじめ外部リソースとの連携も多く用意されています。
Google Cloud Storage
S3から加工したデータを転送し蓄積しています。Google BigQuery から透過的にExternal Table として参照されたり、Workbench インスタンスの Notebook から読み取られて分析に利用されています。
Looker Studio
分析結果を可視化するBIツールです。アナリストや社内のユーザが利用し、分析結果をダッシュボードにして社内へ提供します。
Vertex AI Workbench
Google Cloud の提供するセミマネージド分析環境、JupyterLab の起動するインスタンスを提供し、アナリストなどがPython コードなどでデータ分析できる環境として利用します。機械学習モデルを作成したりする用途で利用できます。
周辺および外部サービス
Google Workspace
Gmail や Google Spreadsheet などの一般的なワークスペースを提供するサービスです。Google Cloud とはID連携しており、認証の仕組みを一元化しています。
Google Groups
権限グループを作成してIAMで認可を与えることができ、Google Cloud の各サービスやリソースへの認可を一元的に管理できるようにしています。
Google Analytics
サービスのユーザの行動ログを記録しています。Google BigQuery にデータを連携し、円滑に分析可能にできます。
Adjust など
Adjust はモバイルアプリのアトリビューションとユーザー行動をトラッキングするためのプラットフォームです。その他外部サービスをいくつか利用していますが、データを BigQuery へ取り込み、分析できるようにします。
3. 移行プロセスとタイムライン
この章では、リプレイスのプロセスを3〜5ヶ月でどのように実行したかを詳細に説明します。移行中に直面した課題や、その克服方法についても触れます。また、少人数のエンジニアリングチームでどのように効率的に作業を進めたか、リスクを最小限に抑えるための手法なども解説します。
2023−09 プロジェクトメンバーの決定
4名のうち専任エンジニア1名、兼任エンジニア1名はセキュリティ部門と兼務、アナリストは通常業務もありつつの対応でした。
- エンジニア:専任1名、兼任1名
- アナリスト:兼任2名
この後人事異動などもあり、最終的にメンバー3名でのプロジェクトでした。
2023−09 アーキテクチャの決定
上述のアーキテクチャを決定しました。
2023-09 セキュリティ要件に関する社内調整
新データ基盤では、既存のデータ基盤である Treasure Data に準ずる統制とすることとし、社内関係部署と折衝して合意しました。
こうした調整は、後々プロジェクトが行き詰まったり、セキュリティ上必要とされる要件に大きなコストを払わなければいけなくなるリスクを、あらかじめ見極めてコントロールするものです。
想定外の要件に大きなコストを払うことなく、データ基盤そのもののリプレイスに注力するために、こうした手続きはプロジェクトの前提として非常に重要でした。
2023−10 クエリ管理方法の決定
Terraform のためのリポジトリ、スキーマやクエリを管理するためのリポジトリなど、いくつか GitHub のリポジトリを作成して管理することとしました。
定期実行クエリについては Airflow 管理のためワークフロー単位で既存のリポジトリがあり、新データ基盤向けのタスクについても、DAGを追加して管理しました。
アドホッククエリに関しては、Git 操作にアナリストが不慣れであったこともあり、Git によるクエリ管理はリプレイス後の課題として棚上げされ、当面BigQuery 上でクエリ管理することとしました。
2023−10 社内向けマニュアルの整備
新データ基盤(Google Cloud)で新旧データの一致が取れれば、社内の一般ユーザに使ってもらうことになります。
まだシステムができていないのに最初からマニュアルを作成するのは順番として変ですが、作りながらメモを残しつつ育てていく方が、最終的に思い出してマニュアル整備するより効率がよいと考え、最初に書き込む場所を作りました。
実際構築の際のメモや使う際に気をつけること、リポジトリや付随する文書へのリンクなど、つど書き留めながら作業をすすめることができるので、作業の目処がある程度ついたころには、自然とマニュアルらしき文章が出来上がっていました。

2023−11 新システムの構築、並行運用開始
最初にテーブルやパーティションの設計を行い、リプレイス前後でほぼ同一の構成を維持しつつ、クエリ効率やコスト効率が改善するように工夫しました。
データの取り込み処理には複数種類あり、Google Analytics や Adjust といったアナリストが管理している外部ツールも存在したため、連携しながら進めました。
Airflow のワークフローは複数階層が連結する構造になっており、rawdata に近い部分から順に新システムへの導入を進めて、数百種類以上あるテーブル群のすべてで、レコード数やサンプルレコードに差分の出ないことを確認しながら進めました。
例
- 1. production の RDS rawdata
- 2. 外部サービスのアプリケーション行動ログ rawdata
- 3. その他外部サービスデータ群 rawdata
- 4. rawdata 群を JOIN して集計した中間テーブル群
- 5. 中間テーブル群を使って集計した各種レポートデータ群
- 6. 等々...
データパイプラインで管理している処理群について、2ヶ月で既存フローと同等のフローを構築し、並列運用が開始できました。

上図は新旧両方のパイプラインが並列実行される定義を示しています。上半分は既存の Treasure Data によるワークフロー、下半分が Google BigQuery によるワークフローになっており、定期処理の中で新旧両方のワークフローが同等に実行され、それぞれの結果を別のファイルに書き出し、検証用のSpreadsheet で、双方の結果の差異が常に確認できるようにしました。
元データが同じため基本的に差異は出ないはずですが、新旧でデータ取り込みのライブラリやSQLが違うため、データ型や関数の違い、微妙なライブラリの挙動の違いで相違が出ることはありました。丁寧に原因を探し潰して行き、最終的に解消できない致命的な差分はありませんでした 🙂
2023−11 データ基盤利用者の権限整備
新データ基盤はリプレイス後には正式に社内に提供することになるため、データ群へのアクセス権管理も、新旧システムで同等に行えるようにしなければなりません。
Treasure Data は独自のユーザアカウントを発行して専用画面で管理をしており、権限ロールを作成してロールをユーザ群に割り当てていました。
Google Cloud では同様に権限ロールを設計し、適切に命名したGoogle Group を作成して適切な権限を与え、そのグループに必要なメンバーの Google アカウントを割り当てて、既存システムと同様の権限が付与されるよう実装しました。
Create and manage Google groups in the Google Cloud console | IAM Documentation

Google Groups でのユーザ管理により、アカウント管理作業は劇的に手軽になりました。定義済みのロールに社内で普及しているGoogle アカウントを割り当てるだけなので、非常にシンプルです。
2023−11 過去データの移設
旧データ基盤には過去数年にわたる大量のデータが残っており、リプレイスする場合にはデータの移設が必要になります。
Treasure Data には外部クラウドとの接続機能が備わっており、接続先に Google BigQuery のデータセットを指定し、Treasure Data 上でテーブルデータをSELECT -> INSERTすることで、すべてのデータをGoogle BigQuery へ Export できました。
Treasure Data のSELECTにはデータ参照量にシビアな上限があり、巨大なデータの場合はクエリを細かく分割しなければならない点が難点ではありました。
SELECTするデータが参照量の上限を超えないボリュームに収まるよう、日付や時間単位でクエリを分割して何度も実行しなくてはならず、かつ先述のように大量に並列で実行するとつまりも発生するため、このデータ抽出は手間と時間がかかる作業になりました。
2023−12 新旧比較
2023年12月の1ヶ月程度をかけ、日次集計結果の新旧比較検証を行いました。
月次集計のレポートもあり、1ヶ月を要したのはその集計結果を見守るためでもありましたが、中間テーブル群やレポート群の数も多く、それなりの箇所で誤差が発生し、調査と検証に時間が必要でした。
テーブル単位で日次集計後のテーブルデータを Treasure Data から BigQuery へ Export して、SQLでテーブルデータの一致を確認するためのクエリを整備して一致確認したほか、Spreadsheet に集計結果を出力している多数のレポートについて、新旧システムでそれぞれ別々のシートに集計結果を出力(フォーマットは同じなので完全一致するはず)して、スプレッドシートの =exact() 関数を使って一括比較でFALSE を探す、といった検証を続けました。

Airflow によるデータ抽出では Treasure Data とBigQuery で異なるライブラリも使用し、Treasure Data の独自関数やデータ型の違いもあり、微妙な挙動の違いから差分が出ることはありました。
例
- Treasure Data の独自関数群(td_time_format とか td_time_range など)の Google BigQuery 関数へ置き換えによる差異
- 中央値を算出する関数のロジックの差異(近似値関数ではもちろん一致しない)
- データ型による精度の違い、丸め誤差
- NULL値の扱いの違い、NULLを無視したりしなかったりの挙動の違い
- 日付フォーマットの違い、時刻型の処理の違い、タイムゾーンのずれ
- cast bigint の挙動の違い、Treasure Data では切り捨て、BigQuery では四捨五入
-
ゼロ割り算をした際、Treasure Data では N/A になり、Bigqueryでは処理が止まる
-
など...
中央値のロジックの違いなどはシンプルかつ奥深いテーマなので、興味のある方は深掘りしてみてください。厳密に原因を突き止めきれなかったものもありましたが、とにかく数値が一致するクエリを試行錯誤して、力技で突破してゆきました。
2023−12 マイルストーンの期日クリア
12月中に新旧数値の一致にも目処がつき、プロジェクト開始時のマイルストーンである2023年内に、契約終了について先方へ連絡できました。
プロジェクトの最もシビアなマイルストーンはクリアしたものの、この後なんらかの致命的な問題があれば行き詰まるため、ひきつづき丁寧な検証が求められました。
2024−01 新データ基盤公開の周知、アドホッククエリ群の移設
広く社内に対して、2024年2月末に旧基盤が廃止されること、データパイプラインで取り込まれた新データ基盤のデータが、既存のデータ基盤と数値一致していること、並列で日次更新されていることを周知しました。
社内の分析ユーザの方々に新データ基盤のマニュアルをお渡ししつつ、簡単なチュートリアルや講習会をひらいて使っていただき、各自の手元にあるアドホックな集計クエリを移行してもらうよう案内しました。
ChatGPTによる Treasure Data と BigQuery のクエリ変換ができるカスタムプロンプトをアナリストのチームで作っていただき、各自のクエリをチャットに投げることで手軽に BigQuery のクエリへ変換できるようになったこともあり、作業は順調に進みました。
移行対象として定期実行されているクエリが数千個単位で存在したため、2ヶ月弱でのクエリ移行もタイトなスケジュールでしたが、上記ツールと社内各所の方々の協力により、無事に移行することができました 🎉
2024−01 定期的なデータバックアップの設定
新データ基盤での定期データバックアップについて、Google Cloud の標準のスナップショットについて動作確認し、定期実行を設定しました。
くわしくは こちらの記事 を参照ください。
2024−02 新データ基盤の利用開始、旧データ基盤の廃止
2024年2月末、旧データ基盤はアクセス停止し、新データ基盤に完全に移行しました。
旧データ基盤で最後に残っていたデータと、記録されていたすべてのクエリ群をAPIでエクスポートし、旧基盤は廃止されました。
4. リプレイスによる成果
コスト目標の達成
🎉 データ基盤のコストは、金額にして数千万円、率にして約90%削減できました! 🎉
この成果は単年のものでなく、今後発生する予定だった年間数千万円のコストを、今後毎年90%削減できたことを指します(この成果だけで、自分には毎年数百万円ボーナスくれても大部分のお釣りがありますよと評価者には強くお伝えしたい 😂)。
既存のシステムで実現していた分析、集計のアウトプットに一切影響を与えずに、単純にコストを削減したので、このリプレイスは成功と言って良いでしょう。
パフォーマンスの向上
コスト削減のみでなく、分析業務のスループットも著しく向上しました。
定期的なクエリが実行されている間、目詰まりを起こしていた現象は一切発生せず、Google BigQuery のパフォーマンスは常に高速でストレスフリーとなりました。
Google Workspace 製品群との円滑な連携
Google Spreadsheet とのデータ入出力や、Looker Studio との連携が非常にスムーズに行えるようになりました。
運用と権限管理の簡素化
社内で導入している Google Workspace との連携により、社内のアカウントをそのままサービスの利用者のアカウントとして管理できるようになり、アカウントの発行削除や認証認可の操作などが平易になりました。
Google Groups による認可を組み合わせることで、権限はよりきめ細かく、権限付与のプロセスは非常に平易に行えるようになりました。
インフラ管理の厳格化
権限設定やインフラの構成情報は Terraform ですべてコード管理されるようになり、構成把握が非常に容易になりました。監査ログも別プロジェクトのBigQuery で分析可能になり、システムの監視もしやすい構成を実現できました。
5. データ基盤リプレイス以後の取り組み
データ基盤のリプレイス以後も継続して、データドリブンな組織の実現と、その先の成長を支えるために取り組みを続けています。
2024-01 データ基盤グループの立ち上げ
データ基盤リプレイスの実務と並行して、社内でのデータ利活用を推進するため、社内データ基盤の運用と拡充に責務を負う組織として、データ基盤グループが組織されました。
社内のリソース事情もあり、当初はデータ基盤のみでなくAWS 開発環境の管理や GitHub、その他開発ツール群の管理など多岐にわたる業務をまとめて引き受けた部門でしたが、業務整理を進め、2024年4月以降はデータに関わる業務に専念できるようになりました。
当時の課題
サービス向け課題
- ダッシュボードなどの日次集計の出力が遅い(前日分の集計完了が翌日昼)。
- サービスの意思決定に利用できる指標・データが揃っていない。
- データ分析に利用できていないデータがまだ多く存在している。
- など...
開発運用向け課題
- 開発・運用向けのデータ利活用が進んでおらず、データが散在して利用しにくい。
- 開発組織が一般的に必要とするデータが可視化できていない。ソフトウェア品質やサービスのパフォーマンス、テストカバレッジ等の数値をいつでも手軽に確認できるようになっていない。
- インシデント対応・調査に利用できるデータと分析環境がない。システムで発生するログはストレージに蓄積されており、調査を行う開発者が手軽に分析できる環境がない。
- など...
2024-04 開発・運用ダッシュボードの提供
DevOps Research and Assessment (DORA)の研究結果に沿った Four Keys の指標や、生産性、サービス品質、コードの複雑度、可読性、収益性、コスト、費用対効果など、開発者や運用者に日々の業務改善に役立つ具体的なフィードバックを提供し、組織全体のパフォーマンスを向上させるための情報をダッシュボードにしました。
Looker Studio を使用したダッシュボードとして提供しており、GitHub ログやソースコード群、AWS やGoogle などのクラウドサービスなどからデータを収集して集計し、日次や週次、任意のディメンジョンでデータを可視化できるようにしています。
まだ可視化できていない情報は多数あり、継続して改善を続けています。

例:API のパフォーマンス指標など

2024-05 日次集計の翌朝確認の実現
ブロックチェーンのシステムはグローバルであることもあって、社内のさまざまなデータはUTCを基準としています。この影響で daily の集計もこれまでUTC基準でなされることが多くありました。
この弊害で、UTC基準で daily の集計値を把握するには 翌朝 09:00 以降に算出するルールで運用されてきた(データが出揃うには昼まで待たなくてはいけなかった)のですが、この集計を JST 基準で出せるように対応しました。
多数存在する中間データ群の集計基準を修正するため一部仕様から変える地道な対応ではあったのですが、この対応を行うことで、他社で一般的な集計サイクルと同様に、JST基準で 00:00 以降に集計することが可能になり、翌早朝のうちには集計結果が得られるようになりました。
日次集計の翌朝確認をさらに進めて、現状は当日の活動結果がダッシュボードでも確認できるようにしており、今後よりリアルタイムなデータ分析が可能になるよう、取り組みを進めています。
2024-06 データカタログとメタデータ更新フローの構築
Google Data Catalogを導入し、データソースを一元化してカタログ化しました。またメタデータの整理もすすめ、テーブルとカラムの説明文を充実させ、ユーザによるデータ理解の向上に寄与しました。
テーブルとカラム説明文のマスタ管理をし、つねに最新の状態でメタデータが更新されるフローを構築しました。
https://cloud.google.com/data-catalog/docs/concepts/overview
2024-08 JupyterLab(Notebook)による分析環境の提供
Google Cloud には Vertex AI Workbench という Notebook 分析環境を提供するサービスがあり、これを利用して、社内のアナリスト、データ分析ユーザ向けに JupyterLab 環境を提供しています。SQLだけでは分析の難しい複雑なデータ分析を、Python などのコードをつかって実現できる環境として社内に提供しています。
機械学習の試行錯誤を行う環境としても位置付けており、データ活用の応用として、今後データ基盤グループでも取り組みを増やしたいと考えています。

2024-09 ログデータの集約
アプリケーションのログ、CDNのログ、Blockchain ノードのログなど、これまでログデータは production 環境に保管され、閲覧のためには必要な権限と承認をもらいストレージから取得する必要がありました。
これは運用負荷が非常に高いため、運用者がアクセスしやすいよう、production データ取り込みと同様のフローにのせてデータ分析環境でログ分析を行えるようにしました。
AWS上のデータ管理環境でデータベースのデータと同様に無害化の処理を施し、機微情報を含まない状態で Google Cloud へ転送し、分析できるようにしています。
この対応で、サービス運用に関わるエンジニアの負荷軽減に貢献できました。
2024-09 自然文によるクエリ生成の精度向上
Gemini in BigQuery を活用することで、自然言語によるクエリ生成が実現しています。
専門的なSQL知識がなくても、ユーザーは日本語自然文でデータに関する質問を行い、すぐに分析結果を得ることが可能になりました。これはデータ利用のハードルを大幅に下げ、データ活用による意思決定プロセスを迅速化することに貢献します。
ただし適切なデータ整備を行わない状態ではクエリ精度は低く、実用の上で課題があります。メタデータをリッチにすることで、自然文からのSQL生成精度を向上させる取り組みを行っています。
Google Cloud を利用することで AIサービスへのアクセスが向上していますが、これらもリプレイスによる恩恵と言えます。実用のためにはまだ工夫の余地がありますが、この精度があがることで、データ利活用の機会を劇的に増やすことができると考えています。
https://cloud.google.com/bigquery/docs/write-sql-gemini

おわりに
ここまでお読みいただきありがとうございました。
今回のデータ基盤リプレイスはコスト削減とパフォーマンス向上を同時に実現し、十分な成果をあげることができました。しかしこのプロジェクトの価値は、単なるインフラの置き換えでなく、コインチェックのデータドリブンな活動を支える基盤が整ったところにあります。
データ基盤のリプレイス以後、運用面やサービス間の連携、AI技術へのアクセスなどにおいて、メリットを感じる場面は多くありました。データを眠らせておくことなく、意思決定に活用する機会がますます増えていくよう、引き続き活動してゆきます。
基盤リプレイス後に取り組んでいるいくつかの案件については、別の記事で後日談を書きたいと考えています。ぜひ、今後の取り組みにもご期待ください!
著者

プロフィール
コインチェック株式会社 開発・人事本部 アプリケーション基盤部 データ基盤グループ グループリーダー
データエンジニアとして Yahoo! やミクシィでデータ分析や機械学習のシステム構築や運用を担当、DeNAで新規事業の立ち上げを経て2023年3月コインチェック入社、CTO室所属で新通貨上場やアプリケーションコードのリファクタリングなどを担当したのち、2024年1月より現職